Computer Vision Explained: How AI 'Sees' the World
From unlocking your smartphone with a glance to powering self-driving cars, computer vision underpins a growing spectrum of AI applications. But how do machines transform raw pixels into actionable intelligence? This in-depth guide unpacks the stages of a typical computer vision pipeline—image acquisition, preprocessing, feature extraction, model training, and advanced tasks such as object detection and semantic segmentation. By understanding these components, developers and decision-makers can harness computer vision to build reliable, scalable systems.
1. Image Formation and Capture
Computer vision begins with image formation: sensors convert visible light into digital signals. Digital cameras and image sensors sample light intensity and color across a grid of pixels. The resolution, dynamic range, and lens quality determine the fidelity of captured images. In specialized settings, thermal cameras, LiDAR, and multispectral sensors extend vision beyond the visible spectrum, enabling night-time navigation, depth sensing, and detection of material properties.
2. Preprocessing and Data Augmentation
Raw images often arrive with noise, lens distortions, or inconsistent lighting. Preprocessing standardizes inputs to improve downstream performance. Key steps include:
- Noise Reduction: Filters such as Gaussian blur smooth pixel variations.
- Color Normalization: Histogram equalization balances contrast; channel scaling aligns training and inference data.
- Geometric Transformations: Cropping, rotation, and perspective correction rectify viewpoints.
- Data Augmentation: Real-time generation of rotated, flipped, or color-shifted images augments training sets—reducing overfitting and improving model generalization.
3. Handcrafted Features vs. Learned Representations
Early computer vision relied on handcrafted descriptors: SIFT, SURF, and ORB capture keypoints and local gradients; HOG emphasizes edge histograms. While effective for controlled tasks (like facial alignment), these methods struggle with complex scenes and varied lighting.
The deep learning revolution supplanted handcrafted features with learned representations. Convolutional Neural Networks (CNNs) automatically discover hierarchical features—edges and corners in early layers, textures and shapes in intermediate layers, and semantic concepts in deep layers. Training end-to-end on large-scale image datasets allows networks to adapt features to specific tasks with minimal manual tuning.
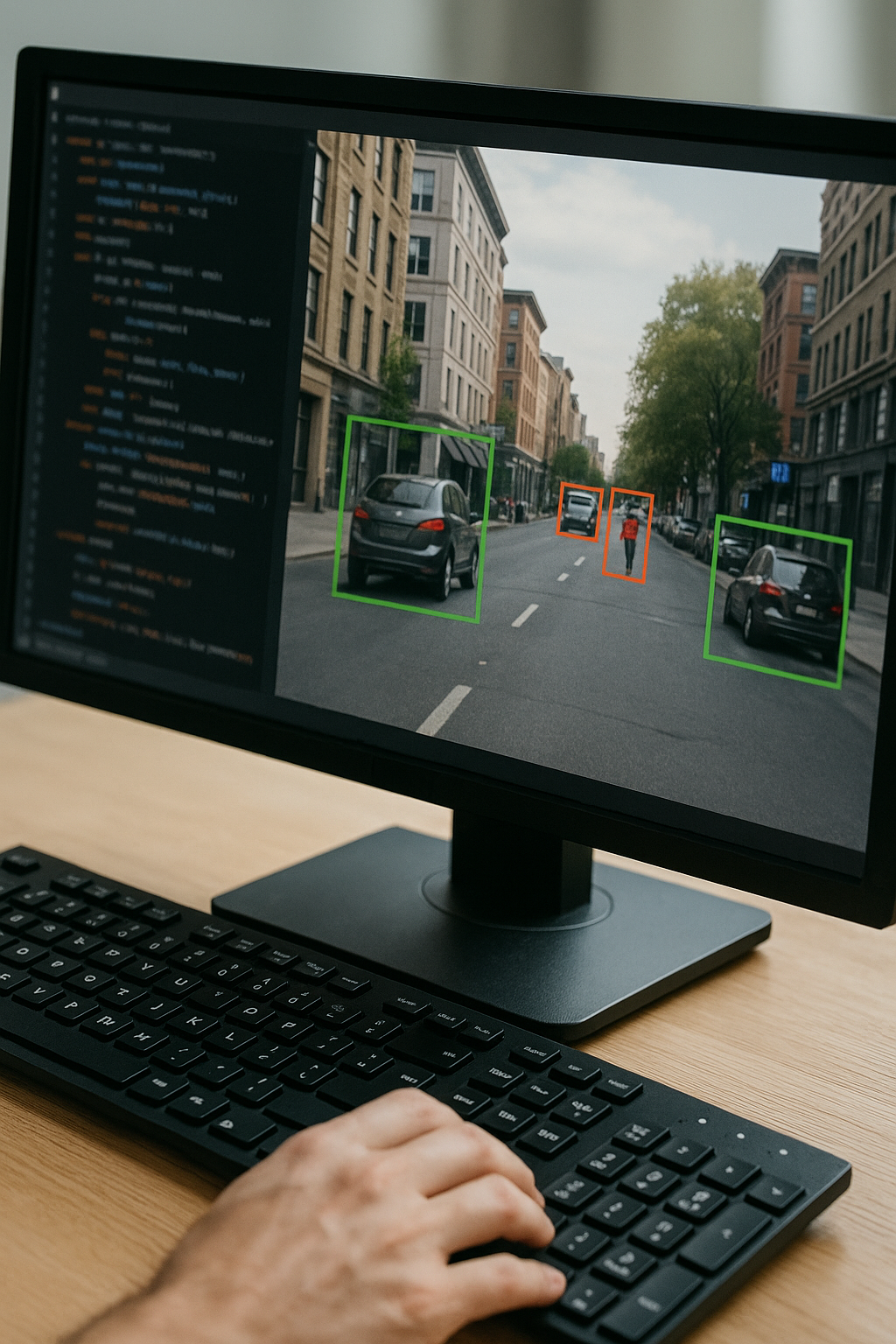
4. Convolutional Neural Networks: Architecture and Training
At the heart of modern computer vision lies the CNN. A typical architecture stacks convolutional layers (learned filters), pooling layers (spatial downsampling), and fully connected layers (global reasoning).
- Convolutional Layers: Apply multiple kernels across the image to produce feature maps. Each kernel learns to detect a visual pattern.
- Pooling Layers: Aggregate activations over local neighborhoods, providing translation invariance and reducing computational load.
- Activation Functions: Non-linearities (ReLU, Leaky ReLU) enable networks to model complex relationships.
- Batch Normalization: Stabilizes learning by normalizing layer inputs, allowing higher learning rates and faster convergence.
Training uses backpropagation and gradient descent: the network iteratively adjusts weights to minimize a loss function (e.g., cross-entropy for classification). Key hyperparameters include learning rate, batch size, and regularization techniques like dropout or weight decay.
5. Advanced Tasks: Detection, Segmentation, and Beyond
Object Detection and Localization
Real-world applications demand not only identifying what objects are but also where they are located. Two popular paradigms dominate:
- Two-Stage Detectors (Faster R-CNN): Generate region proposals then classify and refine bounding boxes. High accuracy at the cost of slower inference.
- Single-Stage Detectors (YOLO, SSD): Predict bounding boxes and class scores in one pass. Balanced speed and accuracy, ideal for real-time systems.
Semantic and Instance Segmentation
Segmentation assigns class labels at the pixel level:
- Semantic Segmentation (e.g., U-Net, DeepLab): Labels every pixel with a class (road, car, pedestrian), useful for scene understanding in autonomous driving.
- Instance Segmentation (e.g., Mask R-CNN): Extends object detection by producing a binary mask for each instance, distinguishing overlapping objects.
Emerging Techniques: Vision Transformers and Self-Supervision
Vision Transformers (ViT) adapt transformer architectures from NLP to vision by splitting images into patches and modeling long-range dependencies. Self-supervised pretraining—learning from unlabeled images using tasks like colorization or contrastive learning—reduces reliance on labeled data and boosts performance on downstream tasks.
6. Deployment Considerations: Edge vs. Cloud
Building a production computer vision system involves trade-offs between latency, privacy, and compute resources:
- Cloud Deployment: Centralized GPUs or TPUs enable large models and batch processing but incur network latency and data transfer costs.
- Edge Deployment: Inference on devices (smartphones, IoT cameras) reduces latency and protects privacy. Model quantization and pruning optimize networks for limited hardware.
Frameworks like TensorFlow Lite, ONNX Runtime, and NVIDIA’s TensorRT simplify deployment across diverse platforms.
7. Challenges and Best Practices
Despite its power, computer vision faces pitfalls:
- Adversarial Vulnerabilities: Small perturbations can fool models—requiring robust training and detection mechanisms.
- Dataset Bias: Imbalanced training data yields poor performance on underrepresented scenarios—addressable through diverse data collection and bias mitigation.
- Explainability: Interpreting deep model decisions remains difficult—techniques like Grad-CAM visualize salient regions, aiding transparency.
Adopting best practices—rigorous validation splits, continuous monitoring, and regular retraining—ensures stable performance in dynamic environments.
Conclusion
Computer vision transforms pixels into insights, powering applications across industries—from healthcare imaging to industrial automation. By demystifying its core components, from preprocessing to advanced segmentation, we empower practitioners to build robust, scalable vision systems.
Eager to stay updated on the latest in AI and computer vision? Subscribe to our newsletter for hands-on tutorials, model demos, and research breakthroughs—delivered straight to your inbox.
Sign Up For Our Weekly Newsletter and Get Your FREE Ebook " AI For Everyone - Learn the Basics and Embrace the Future"









